
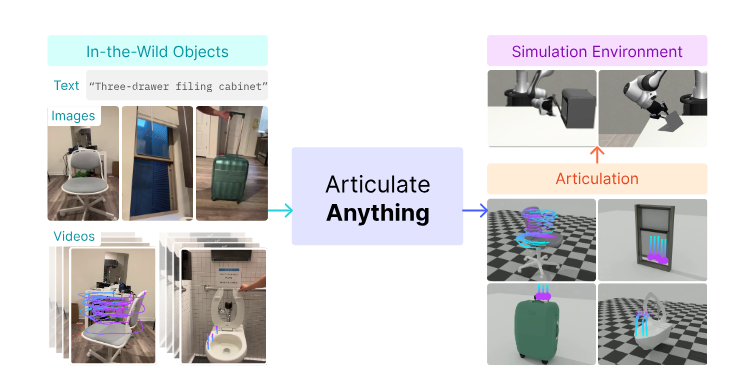
This blog post discusses a research paper that introduces Articulate-Anything, a groundbreaking system for automatically generating articulated 3D models. This system is a game-changer for fields like AR/VR, animation, and robotics, where creating realistic 3D models is often a time-consuming and expert-driven process.
Articulate-Anything is a system that automates the creation of articulated 3D objects from diverse inputs such as text, images, and videos. It uses vision-language models (VLMs) to generate Python code, which is then compiled into URDF (Unified Robot Description Format) files. These URDF files are compatible with standard 3D simulators, allowing for the creation of interactive digital twins. The system's clever approach uses an actor-critic method: a VLM actor proposes solutions, and a VLM critic evaluates and refines them iteratively, leading to highly accurate and realistic models.
The magic behind Articulate-Anything lies in its three-stage process:
Mesh Retrieval: The system starts by retrieving 3D meshes from a library (like PartNet-Mobility) based on the input. For visual inputs, it uses CLIP similarity for efficient retrieval. Text inputs are processed by an LLM to predict object parts and their dimensions.
Link Placement: An actor-critic VLM system iteratively places the retrieved meshes in 3D space. The actor generates Python code for placement, while the critic assesses the result based on visual similarity to the input and provides feedback for refinement.
Joint Prediction: Another actor-critic system predicts the kinematic joints between the placed meshes. Similar to link placement, the actor generates Python code, and the critic evaluates and refines based on video input (if available) to ensure accurate joint movement.
The generated Python code is then compiled into the URDF format, making the models ready for use in any standard 3D simulator.
Articulate-Anything significantly surpasses existing methods. On the PartNet-Mobility dataset, it boasts a remarkable 75% success rate, a huge leap from the 8.7-12.2% achieved by previous techniques. The system's ability to handle complex objects and ambiguous affordances from various input types is truly impressive. Furthermore, the generated models have proven useful for training advanced robotic manipulation policies.
While Articulate-Anything is a significant breakthrough, there are still some challenges to address:
Data Dependency: The system's performance heavily relies on the quality and completeness of the underlying 3D asset dataset. Improving the system's generalization to unseen objects requires addressing this dependency.
Computational Cost: Training and running the VLMs demand substantial computational resources.
Complexity: The system's architecture is complex, which could make maintenance and expansion difficult.
Generalization: Further testing on diverse datasets is crucial to fully assess its generalization capabilities.
Future research could explore several exciting avenues:
Improved Mesh Generation: Integrating more advanced mesh generation models could enhance the quality and realism of the generated assets.
More Diverse Datasets: Expanding the datasets used for evaluation would provide a more comprehensive understanding of the system's capabilities.
Enhanced Critic Design: More sophisticated critic models could further improve accuracy and efficiency.
Real-time Articulation: Optimizing the system for real-time articulation generation would open up exciting interactive applications.
Articulate-Anything is a significant step forward in automatic articulated object modeling. Its accuracy, robustness, and versatility across various input modalities showcase its potential to revolutionize many fields. Addressing the current challenges and exploring the future directions mentioned above will pave the way for even more impressive advancements in the future.
