
Federated learning (FL) has emerged as a powerful tool for training models on decentralized datasets without compromising data privacy. However, FL faces challenges when dealing with Non-Independent and Identically Distributed (Non-IID) data across participating clients. While previous research focused on label or concept shifts, this paper dives into the impact of covariate shifts—variations in data distributions—on the performance of federated learning for 2D semantic segmentation.
We find that covariate shifts, although less impactful than label shifts, still hinder convergence in FL for semantic segmentation. To address this, we propose a novel framework called Sample Clustered Federated Learning (SCFL). This innovative approach significantly improves convergence speed and generalization performance compared to existing techniques.
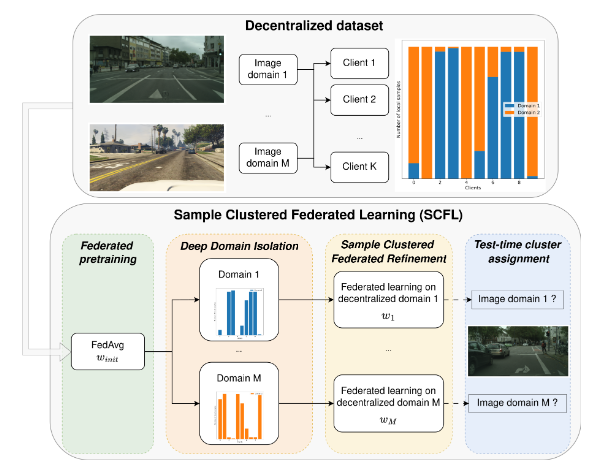
Covariate shifts represent differences in the underlying feature distributions of data across clients. Unlike label shifts (differences in class distributions) or concept shifts (differences in task definitions), covariate shifts affect the model's ability to generalize to unseen data. Existing personalized and clustered federated learning methods often fall short in scenarios where each client's data encompasses multiple underlying feature domains. These methods typically operate at the client level, assuming homogeneity within each client's dataset. This assumption is frequently violated in real-world applications.
SCFL introduces a sample-level clustering approach to overcome these limitations. It leverages a novel technique called Deep Domain Isolation (DDI) to identify and isolate image domains directly in the model's gradient space. This is achieved using a Federated Gaussian Mixture Model (Fed-GMM) and spectral clustering. The key steps of SCFL are:
Experiments were conducted on both synthetic (TMNIST-Inv) and real-world (Cityscapes+GTA5) datasets with various data splits (IID, Full non-IID, Dirichlet non-IID) to simulate different levels of data heterogeneity. The results demonstrate:
SCFL presents a robust framework for handling covariate shifts in federated learning for semantic segmentation. Its sample-level approach improves convergence, generalization, and offers a solution that is agnostic to test distribution assumptions.
Future research could explore alternative clustering techniques, investigate the impact of different model architectures, extend SCFL to handle multiple types of Non-IID data, and apply it to other computer vision tasks. Further investigation into computational efficiency and scalability is also warranted.
