
Large language models (LLMs) are amazing, but they can sometimes produce outputs that are untrue, biased, toxic, or even harmful – especially when tricked with "jailbreak" prompts. Existing methods for detecting this misbehavior often focus on a single problem or analyze only the LLM's output. But what if we could look inside the LLM's "brain" to catch bad behavior in the act?
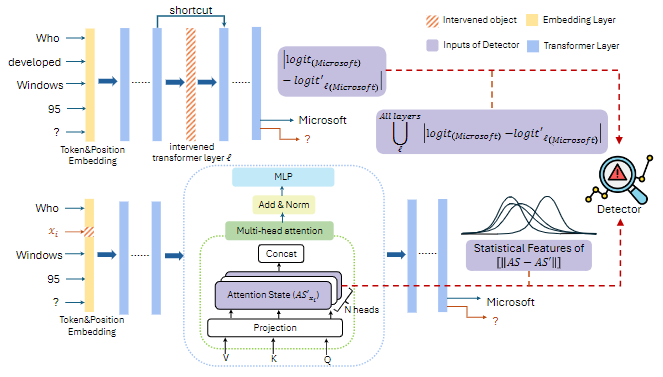
That's the idea behind LLMSCAN, a new technique detailed in the research paper "LLMSCAN: Causal Scan for LLM Misbehavior Detection". Instead of just examining the final output, LLMSCAN uses causality analysis to monitor the LLM's internal processes. Think of it as a lie detector for LLMs, but one that analyzes the LLM's internal "thought process" rather than just its words.
LLMSCAN works in two stages:
Scanning: A "scanner" uses lightweight causality analysis to create a "causal map" of the LLM's internal activity. This involves:
Detection: A simple classifier (a Multi-layer Perceptron, or MLP) is trained on these causal maps. It learns to distinguish between causal maps from normal LLM behavior and those indicating misbehavior. The model uses statistical features (like mean, standard deviation, etc.) from the token-level analysis to create a consistent input for the classifier, regardless of the input length.
The researchers tested LLMSCAN on four popular LLMs and thirteen datasets covering four types of misbehavior:
The results were very promising! LLMSCAN achieved an average AUC (Area Under the Curve) score above 0.95 for lie detection, jailbreak detection, and toxicity detection – indicating high accuracy. While the performance on bias detection was slightly lower, it still significantly outperformed the baselines (existing methods). Importantly, LLMSCAN can often detect misbehavior early in the generation process, before the full output is even generated.
While LLMSCAN shows great promise, there are some areas for improvement:
Future work could focus on expanding the types of misbehavior detected, optimizing the causality analysis for efficiency, using more advanced machine learning models for the detector, and integrating LLMSCAN into real-time LLM monitoring systems.
LLMSCAN offers a novel and effective approach to detecting LLM misbehavior. By analyzing the internal workings of the LLM, rather than just its output, it achieves high accuracy and efficiency across various types of misbehavior. This generalizable approach addresses limitations of existing methods, paving the way for more robust and comprehensive LLM safety mechanisms. It's a significant step toward making LLMs safer and more reliable.
